
期刊信息
Navigation
曾用名:江海侨声
主办:江苏省政府侨办
ISSN:1006-0278
CN:32(Q)第0001?
语言:中文
周期:月刊
被引频次:1625
期刊分类:政治学
华人博士生发布基于Transformer的视频生成器,IC
【作者】网站采编
【关键词】
【摘要】:来源:ICML 2021 编辑:LRS 【导读】Transformer能处理文字、图片,如今又进军视频领域!Bengio的徒孙、罗格斯大学华人博士生发布了一个视频版GPT-3,基于Transformer的视频生成器,ICML 2021已来源:ICML 2021
编辑:LRS
【导读】Transformer能处理文字、图片,如今又进军视频领域!Bengio的徒孙、罗格斯大学华人博士生发布了一个视频版GPT-3,基于Transformer的视频生成器,ICML 2021已发表。
Transformer已经成了当下「最牛」的基础模型,在NLP、CV领域无往而不利。一些基于Transformer预训练模型BERT、GPT对于下游任务,如问答、阅读理解、文本摘要等都有很好的促进作用。

GPT主要关注文本生成,并且取得了不错的成就,但到目前为止,视频生成还没有一个很完善的预训练模型。
基于Transformer的视频生成中,主要难点在于:
1、如何对视频进行切割(tokenize)
2、如何序列化这些分隔后的片段(token)。与文本中的token不同,文本的符号是自然有序的。
之前对图像和视频的相关工作主要是在像素级别进行操作,将图像平坦化(flatten out)为像素序列。然而,由于Transformer中使用的自注意层的存储和计算在输入序列长度上是二次复杂度的,为了有效地训练这些模型,这些工作要么降低图像的分辨率,要么在整个图像或视频中使用局部注意而不是全局注意力。
针对这个问题,罗格斯大学的博士生Yi-Fu Wu提出了一个新模型OCVT,以对象为中心的表示与使用自回归对象级下一帧预测目标训练的Transformer相结合,论文已经发表在ICML 2021上了。他是斯坦福大学的理学硕士和伊利诺伊大学厄巴纳-香槟分校的理学学士,最近的研究主要关注非监督表征学习。

他的导师是Sungjin Ahn,曾经在MILA的 Yoshua Bengio 收下做过深度学习的博士后。他是罗格斯大学认知科学计算机科学中心的助理教授,领导着罗格斯大学的机器学习小组。主要研究目标是解决核心机器学习问题,开发通用的问题解决代理。特别强调无监督和结构化学习的世界模型和表示使用深度学习,概率学习,和强化学习。也喜欢从认知科学和神经科学中得到启发,去寻找新奇的问题和适当的归纳偏见。他在加州大学欧文分校获得了博士学位,在 Max Welling 教授的指导下研究可扩展的近似贝叶斯推断。

在这篇论文中,研究人员提出了一种不同的方法来解决Transformer中自注意力二次时间复杂度。在对象级(object)粒度上平衡归纳偏见(inductive bias),对于许多下游任务是有益的,特别是在对象相互作用的场景中。
为此,他们研究了标记化和序列化视频的不同设计选择,并提出了以对象为中心的视频转换器(Object-Centric Video Transformer, OCVT)。
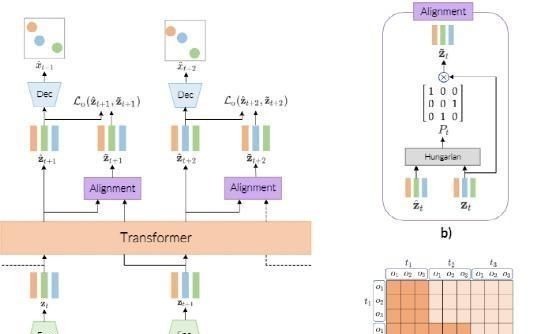
在OCVT中,将以对象为中心的表示与使用自回归对象级下一帧预测目标训练的Transformer相结合。
模型利用了一类以对象为中心的潜在表示,它可以学习结构化表示而无需对象级标记。所学习的对象表示包括关于每个视频帧中的对象的显式位置和大小信息。用它来寻找两帧之间物体的二部匹配,这样就可以构造面向对象的损失函数。以对象为中心的Transformer的使用允许OCVT学习视频中对象之间的空间和长期时间交互。
解码器使用一系列反褶积层(deconvolution layer)为每个对象创建图像。z^(pres)用于确定对象的透明度,一个较低的值将导致对象不出现在重建图像中。
然后将空间Transformer与z^(where)一起使用,将每个对象放置到最终重建图像上。对于背景不能完全被物体覆盖的场景,还训练了一个完全卷积的背景模块来生成背景隐藏z^g。
在这种情况下,还生成一个前景遮罩α,用于控制最终渲染图像中前景对象和背景之间的权重。
为了建模对象随时间的动态性,使用了一个Transformer解码器,其中的输入是以对象为中心的隐向量z^t。与其他模型使用RNN相比,Transformer既能建模时间的动态性,并且也不要求一个分离的交互式模型。除此之外,尽管RNN能够保存过去状态的隐藏层,但Transformer直接访问过去的隐藏层,显然能够更直接地建模长距离的词依赖。
除此之外,研究人员还对时间步长t使用正弦编码,类似于原始Transformer(Attention is All you Need论文中说的)中的位置编码作为Transformer解码器的输入。而且他们对传统transformer解码器中的因果注意遮罩(casual attention mask)进行了改进,使得一个时间步长内的对象可以相互产生注意。
文章来源:《华人时刊》 网址: http://www.hrskzz.cn/zonghexinwen/2021/1113/1366.html