
期刊信息
Navigation
曾用名:江海侨声
主办:江苏省政府侨办
ISSN:1006-0278
CN:32(Q)第0001?
语言:中文
周期:月刊
被引频次:1625
期刊分类:政治学
华人博士生发布基于Transformer的视频生成器,IC(2)
【作者】网站采编
【关键词】
【摘要】:当一个物体在图像中移动时,它可能会在不同的时间步被不同的网格单元检测到,因为在帧之间使用了object-wise loss,所以还需要进行模型对齐(object ali当一个物体在图像中移动时,它可能会在不同的时间步被不同的网格单元检测到,因为在帧之间使用了object-wise loss,所以还需要进行模型对齐(object alignment)。
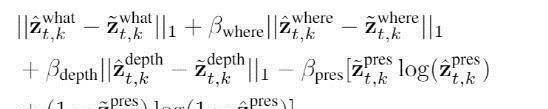
也就是说,需要VAE推断的隐向量z^t中的对象与transformer预测的隐向量具有相同的顺序。
需要注意的是,Transformer的输入不需要跨时间步对齐,因为面向对象的自注意力作用于一组无顺序的对象。对齐主要使用1955年提出的Hungarian算法。
最后主要面向以下四个问题设计实验:
(1)模型能否捕捉到场景复杂的长期时空依赖关系?
(2)该模型能否有效地生成视频?
(3) 模型能否提供良好的表示,以便在下游任务中使用
(4) 设计选择的有效性,及有效的程度,包括以对象为中心的表示、用于动力学预测的Transformer、场景预测与自回归组件预测
从下表可以看到OCVT在所有四个数据集上都达到了最高的精度。ConvVT在Mod1数据集上也有很好的表现,但是在其他需要长期依赖关系的数据集上,精确度会下降。这表明了在对象级时空交互建模中使用以对象为中心的表示的有效性。
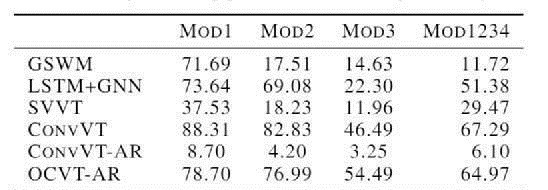
此外,还应注意到基于RNN的模型(GSWM和LSTM+GNN)的模拟性能下降,这表明使用RNN对非常长期的依赖关系进行建模的局限性。自回归生成场景的模型(OCVT-AR和ConvVT-AR)的性能不如非自回归模型。尤其是convt-AR,似乎根本无法正确地对这项任务进行建模,其精确度低于random(0.2,5列)。这可能是因为在这些模型中生成单个图像需要多次通过变换器,并且任何预测误差都可能是复合的。
此外,OCVT-AR需要模型根据对象的位置正确地学习对象的顺序,这可能不是一项容易的任务。
为了强调前期轨迹,像素MSE评价指标是最具信息性的,绘制评价曲线直到它们变平,而不是到达轨迹的末端。
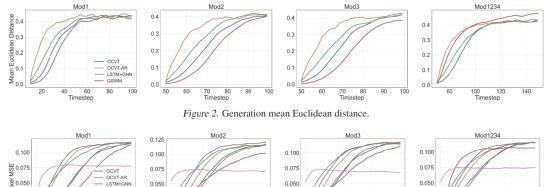
可以注意到GSWM在这种设置下获得了最佳的平均欧氏距离和像素MSE。这并不奇怪,因为GSWM的object-RNN只编码一个球的轨迹,与其他对象的动力学无关。
由于动力学的预测只依赖于最后几个时间步,因此不需要对长期依赖性进行建模。交互作用是由一个单独的图形神经网络处理,也很好地从轨迹建模分离。
另一方面,OCVT需要学习执行更复杂的操作,即在考虑交互的同时分解出自己的轨迹。此外,由于GSWM是端到端训练的,因此它能捕捉到潜变量中的动力学信息,有助于进行轨迹预测。有趣的是,
尽管如此,OCVT仍然可以合理地学习动态,优于其他基线。此外,GSWM的训练程序相比OCVT需要四倍长的时间来收敛,这也会导致不稳定的训练,尤其是对于较长的轨迹,Mod1234实验证明了GSWM不能很好地学习动力学。
下图显示了Mod1数据集上不同模型的长距离生成结果。图中显示了前20个预测step,可以看到GSWM预测的球的位置非常接近地面真实情况,但是在预测球的颜色变化时会出现一些错误。
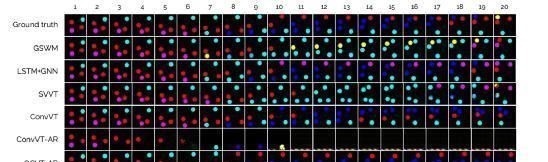
例如,在第7帧中,它错误地预测紫色球应该变成黄色而不是青色。类似地,LSTM+GNN和ConvVT错误地预测了球的颜色(例如,对于LSTM+GNN,第10帧处的紫色球和对于ConvVT,第10帧处的蓝色球),同时也具有比GSWM更差的动力学预测。SVVT的动力学性能甚至比其他模型差,而且还可以预测混合颜色的球。
ConvVT-AR预测在几帧之后丢失的球,结果在比其他模型更低的像素MSE处出现平台,即使生成明显不正确。OCVT-AR比地面真帧更早预测颜色变化,因为不准确的动力学以及不正确的颜色变化(例如第14帧中的紫罗兰球)
参考资料:
文章来源:《华人时刊》 网址: http://www.hrskzz.cn/zonghexinwen/2021/1113/1366.html